
Why Substainability is an Observability Problem ?
Out here, generative AI runs loose, like an open frontier. Teams building platforms sprint behind the scenes - tracking delays, false outputs, how many tokens get used - yet overlook one cost hiding in plain sight: power drawn and emissions left behind.
Funny thing about 2026 - “Responsible AI” keeps showing up in boardroom talks as some rule-following chore. Yet if you’re building platforms, it looks different. Turns out sustainability isn’t policy noise; it hides inside visibility gaps. Watch the system close enough, and ethics start appearing in logs.
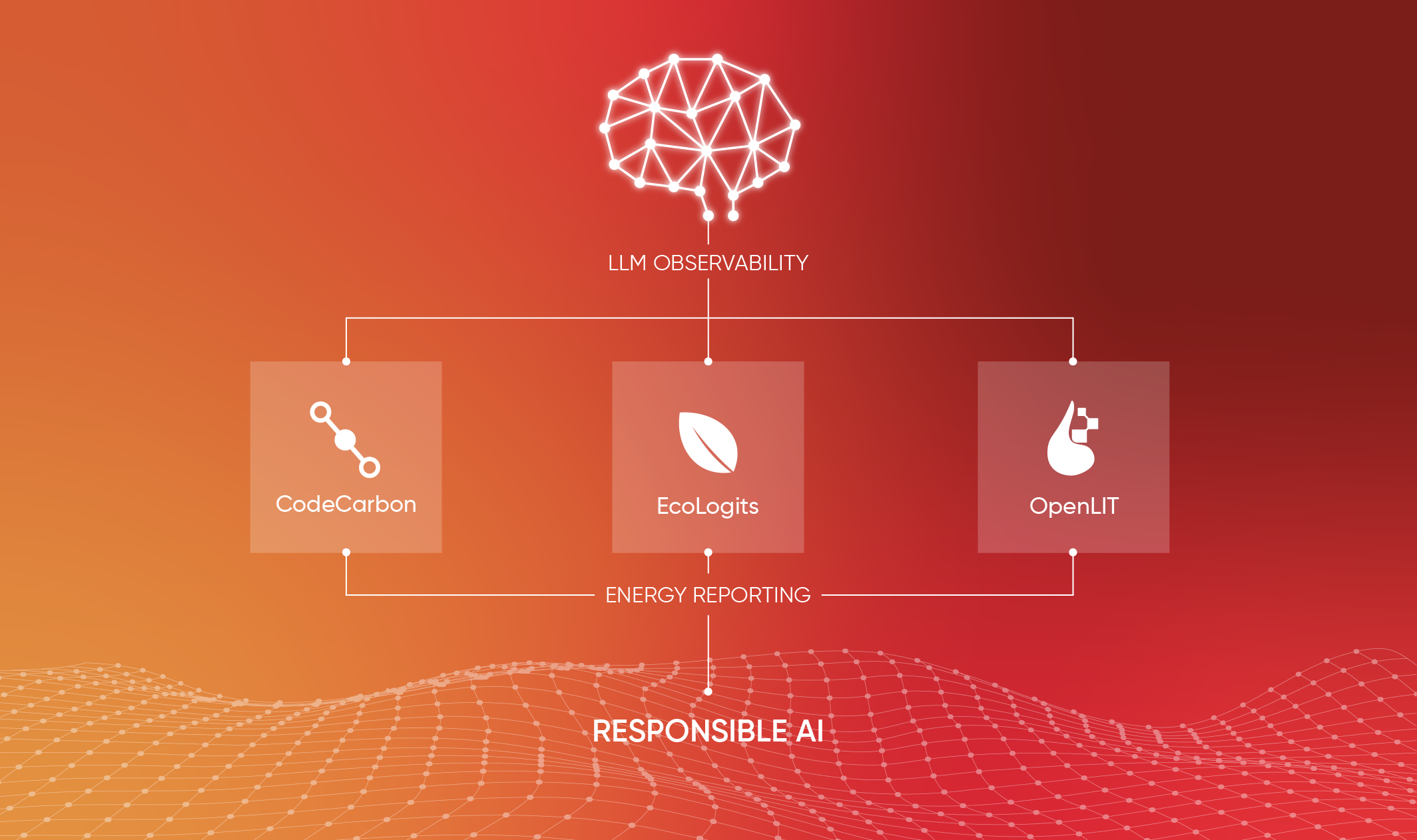
If you cannot measure Joules per inference, you cannot credibly claim your AI systems are efficient or responsible. This post outlines how to build a unified “GreenOps” telemetry stack using:
-
eBPF-based energy attribution (Kepler)
-
LLM semantic tracing (OpenTelemetry + OpenLIT)
-
Carbon impact estimation (CodeCarbon)
-
Unified dashboards and actionable metrics
The GreenOps Stack: eBPF, OpenLIT and CodeCarbon
Down near the metal, most monitoring tools vanish. Latency stats get logged, tokens per second tracked - yet what's actually happening on the hardware slips away. Power use by GPUs? Often left unmeasured. Energy burned across servers? Seldom counted. Even less seen: how clean or dirty the electricity supply really is.
To close that gap, platform teams need to merge three telemetry layers already in use:
-
The Power Layer: Kernel and hardware level energy attribution.
-
The LLM Context Layer: Semantic visibility into prompts, models, and token flow.
-
The Sustainability Layer: Mapping energy to carbon emissions and operational impact.
Energy Attribution with eBPF and Kepler
LLM workloads are notoriously difficult to measure accurately, GPUs often shared across pods, and traditional cgroup metrics rarely reflect true power draw. To get closer to “ground truth,” you can leverage Kepler (Kubernetes Efficient Power Level Exporter).
Kepler uses eBPF kernel tracepoints and hardware energy counters (RAPL for CPUs, NVML for NVIDIA GPUs) to attribute power consumption to specific PIDs and Kubernetes pods, exporting energy metrics into Prometheus without changing a single of code.

Using OpenLIT to add LLM Semantic Context Meaning
Energy metrics alone are just numbers, and numbers by themselves tell half the story. To make them actionable, you need to know: Which model generated the load? Did a specific prompt spike consumption?
OpenLIT extends OpenTelemetry with GenAI specific semantic conventions. It autoinstruments frameworks like OpenAI, LangChain, and Ollama to emit spans containing model names, token counts, and request metadata.
Implementing Joules per Token (JPT) for Responsible AI
While efficiency gains rise, tracking power used per output token takes center stage across platforms. Because impacts matter more now, each unit of generated text gets weighed against its electricity footprint. Yet not every company reports it the same way, still creating gaps in true comparison. Even so, progress leans toward transparency when measuring what fuels machine-generated words.
The "Golden Metric" is Joules per Token (JPT).

Starting from Kepler’s energy deltas, linked to OpenLIT’s token throughput, we can calculate the physical efficiency of our models. JPT allows you to justify technical optimizations—like moving from FP16 to INT8 quantization—using physical data rather than just latency targets.
Mapping energy use to carbon emissions with CodeCarbon
Once power is measurable, the final step is impact. CodeCarbon is a lightweight open-source library that maps energy usage to carbon intensity coefficients based on your specific cloud region.
While Kepler tracks the cluster, CodeCarbon provides the Carbon Receipt for specific jobs or experiments. It allows you to report that an inference task in a "dirty" grid region produced significantly more CO2e than the same task in a "clean" region
The GreenOps Control Loop
Using Grafana as dashboarding you can join these datasets - correlating Kepler metrics with OTel traces. It allows you to jump directly to a trace that shows the exact JPT for that request and creates the "GreenOps Control Loop" where you can alert on energy regressions just as you would on error rates, answering questions like:
| Metric | Tool | Question |
| Joules per Request | Kepler + OTel | Are my inference workload becoming effitient? |
| JPT | Kepler + OpenLit | Which model deliver the best energy/token efficiency? |
| Grid Intensity | CodeCarbon | Should we shift workload to cleaner datacenters ? |
Sustainability isn't a future talk, it's an Operational Reality
Leveraging existing open source solutions - combining eBPF-based energy telemetry, OTel semantic context and carbon impact estimation, you can move sustainability from a corporate aspiration to a measurable operational reality - making it part of your SRE toolkit.
— — —
JPT Benchmarks: Luccioni, A. S., et al. (2023). Estimating the Carbon Footprint of BLOOM. This study provided the baseline data for energy consumption in large-scale LLM deployments.
Carbon Mapping: Schmidt, K., et al. (2021). CodeCarbon: Tracking the Carbon Footprint of Machine Learning Code. The methodology behind mapping hardware energy to CO2e.
The Kepler Project (CNCF). Technical documentation on using eBPF for pod-level power metrics.
OpenTelemetry Semantic Conventions for Generative AI. The official specification for standardized AI telemetry.

Never miss an update.
Subscribe for spam-free updates and articles.